5 Leveraging Micro-Sleep Opportunities in 802.11
In this chapter, we revisit the idea of packet overhearing as a trigger for sleep opportunities, and we take it one step further to the range of microseconds. To this end, we experimentally explore the timing limitations of 802.11 cards. Then, we analyse 802.11 to identify potential micro-sleep opportunities, taking into account practical CSMA-related issues (e.g., capture effect, hidden nodes) not considered in prior work.
Building on this knowledge, we design \(\mu\)Nap, a local standard-compliant energy-saving mechanism for 802.11 WLANs. With \(\mu\)Nap, a station is capable of saving energy during packet overhearing autonomously, with full independence from the 802.11 capabilities supported or other power saving mechanisms in use, which makes it backwards compatible and incrementally deployable.
Finally, the performance of the algorithm is evaluated based on our measurements and real wireless traces. In a brief discussion of the impact and applicability of our mechanism, we draw attention to the need for standardising hardware capabilities in terms of energy in 802.11.
5.1 State Transition Times in 802.11 Cards
From the hardware point of view, the standard Power Save (PS) mechanism requires supporting two states of operation: the awake state and the sleep state. The latter is implemented using a secondary low-frequency clock. Indeed, it is well-known that the power consumption of digital devices is proportional to the clock rate (Zhang and Shin 2012). In fact, other types of devices, such as microcontroller-based devices or modern general-purpose CPUs, implement sleep states in the same way.
For any microcontroller-based device with at least an idle state and a sleep state, one would expect the following behaviour for an ideal sleep. The device was in idle state, consuming \(P_\mathrm{idle}\), when, at an instant \(t_\mathrm{off}\), the sleep state is triggered and the consumption falls to \(P_\mathrm{sleep}\). A secondary low-power clock decrements a timer of duration \(\Delta t_\mathrm{sleep} = t_\mathrm{on} - t_\mathrm{off}\), and then the expiration of this timer triggers the wake-up at \(t_\mathrm{on}\). The switching between states would be instantaneous and the energy saving would be
\[\begin{equation} E_\mathrm{save} = (P_\mathrm{idle} - P_\mathrm{sleep}) \cdot \Delta t_\mathrm{sleep} \tag{5.1} \end{equation}\]
This estimate could be considered valid for a time scale in the range of tens of milliseconds at least, but this is no longer true for micro-sleeps. Instead, Figure 5.1 presents a conceptual breakdown of a generic micro-sleep.
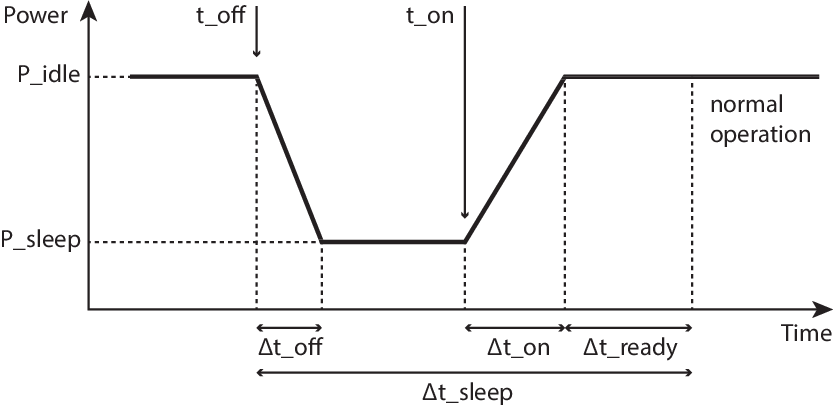
Figure 5.1: Generic sleep breakdown.
After the sleep state is triggered at \(t_\mathrm{off}\), it takes \(\Delta t_\mathrm{off}\) before the power consumption actually reaches \(P_\mathrm{sleep}\). Similarly, after the wake-up is triggered at \(t_\mathrm{on}\), it takes some time, \(\Delta t_\mathrm{on}\), to reach \(P_\mathrm{idle}\). Finally, the circuitry might need some additional time \(\Delta t_\mathrm{ready}\) to stabilise and operate normally. Thus, the most general expression for the energy saved in a micro-sleep is the following:
\[\begin{equation} \begin{split} E'_\mathrm{save} =&~ E_\mathrm{save} - E_\mathrm{waste} \\ =&~ (P_\mathrm{idle} - P_\mathrm{sleep}) \cdot (\Delta t_\mathrm{sleep} -\Delta t_\mathrm{ready}) \\ &- \int_{\Delta t_\mathrm{off} \cup \Delta t_\mathrm{on}} (P - P_\mathrm{sleep}) \cdot dt \end{split} \tag{5.2} \end{equation}\]
where we have considered a general waveform \(P(t)\) for the transients \(\Delta t_\mathrm{off}\) and \(\Delta t_\mathrm{on}\). \(E_\mathrm{waste}\) represents an energy toll per sleep when compared to the ideal case.
Our next objective is to quantify these limiting parameters, which can be defined as follows:
- \(\Delta t_\mathrm{off}\)
- is the time required to switch from idle power and to sleep power consumption.
- \(\Delta t_\mathrm{on}\)
- is the time required to switch from sleep power to idle power consumption.
- \(\Delta t_\mathrm{ready}\)
- is the time required for the electronics to stabilise and become ready to transmit/receive.
The sum of this set of parameters defines the minimum sleep time, \(\Delta t_\mathrm{sleep,min}\), for a given device:
\[\begin{equation} \Delta t_\mathrm{sleep,min} = \Delta t_\mathrm{off} + \Delta t_\mathrm{on} + \Delta t_\mathrm{ready} \tag{5.3} \end{equation}\]
Performing this experimental characterisation requires the ability to timely trigger the sleep mode on demand. As stated in Section 4.1, most COTS cards are not suitable for this task, because they implement all the low-level operations in an internal proprietary binary firmware. However, those cards based on the open-source driver ath9k, like the one presented in previous chapters35 are well suited for our needs. The driver has access to very low level functionality (e.g., supporting triggering the sleep mode by just writing into a register).
This characterisation follows the setup depicted in Section 3.4, Figure 3.7. The card under test is associated to an access point (AP) in 11a mode to avoid any interfering traffic from neighbouring networks. This AP is placed very close to the node to obtain the best possible signal quality, as we are simply interested in not losing the connectivity for this experiment. With this setup, the idea is to trigger the sleep state, then bring the interface back to idle and finally trigger the transmission of a buffered packet as fast as possible, in order to find the timing constraints imposed by the hardware in the power signature. From an initial stable power level, with the interface associated and in idle mode, we would expect a falling edge to a lower power level corresponding to the sleep state. Then the power level would raise again to the idle level and, finally, a big power peak would mark the transmission of the packet. By correlating the timestamps of our commands and the timestamps of the measured power signature, we will be able to measure the limiting parameters \(\Delta t_\mathrm{off}, \Delta t_\mathrm{on}, \Delta t_\mathrm{ready}\).
The methodology to reproduce these steps required hacking the ath9k driver to timely trigger write operations in the proper card registers, and to induce a transmission of a pre-buffered packet directly in the device without going through the entire network stack. A simple hack in the ath9k module36 allows us to perform the following experiment:
- Initially, the card is in idle state, connected to the AP.
- A RAW socket (Linux
AF_PACKETsocket) is created and a socket buffer is prepared with a fake packet. - \(t_\mathrm{off}\) is triggered by writing a register in the card, which has proved to be almost instantaneous in kernel space.
- A micro-delay of 60 \(\mu\)s is introduced in order to give the card time to react.
- \(t_\mathrm{on}\) is triggered with another register write.
- Another timer sets a programmable delay.
- The fake frame is sent using a low-level interface, i.e., calling the function
ndo_start_xmit()from thenet_deviceoperations directly. By doing this, we try to spend very little time in kernel.
The power signature recorded as a result of this experiment is shown in Figure 5.2 (left).
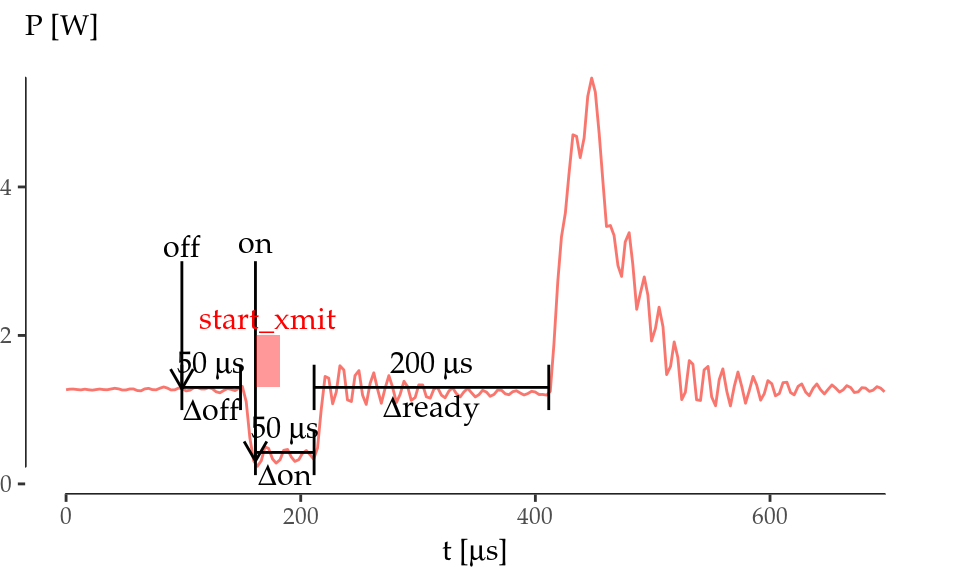
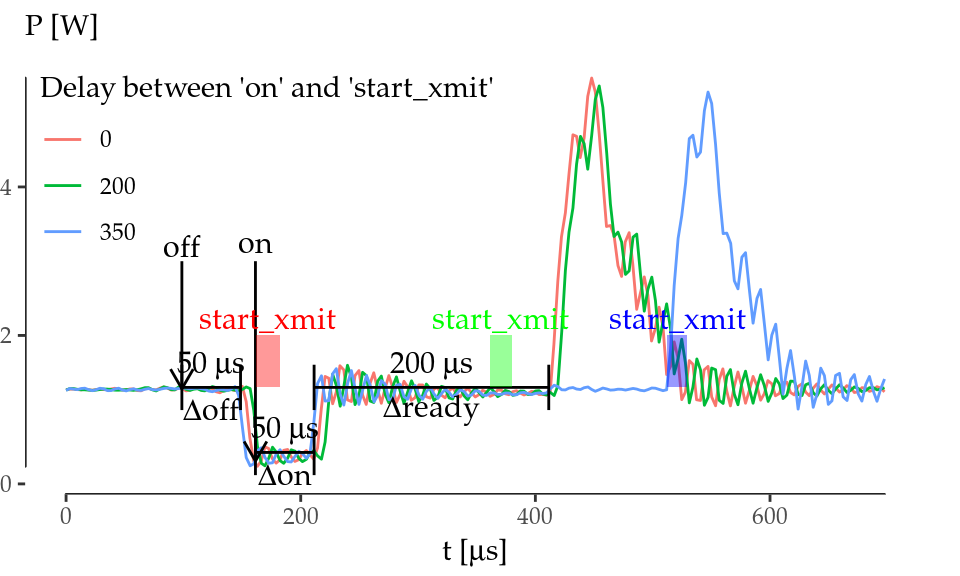
Figure 5.2: Atheros AR9280 timing characterisation.
As we can see, the card spends \(\Delta t_\mathrm{off} = 50\) \(\mu\)s consuming \(P_\mathrm{idle}\) and then it switches off to \(P_\mathrm{sleep}\) in only 10 \(\mu\)s. Then, \(t_\mathrm{on}\) is triggered. Similarly, the card spends \(\Delta t_\mathrm{on} = 50\) \(\mu\)s consuming \(P_\mathrm{sleep}\) and it wakes up almost instantaneously. Note that the transmission of the packet is triggered right after the \(t_\mathrm{on}\) event and the frame spends very little time at the kernel (the time spent in kernel corresponds to the width of the rectangle labelled as start_xmit in the graph). Nonetheless, the card sends the packet 200 \(\mu\)s after returning to idle, even though the frame was ready for transmission much earlier.
To understand the reasons for the delay in the frame transmission observed above, we performed an experiment in which frame transmissions were triggered at different points in time by introducing different delays between the \(t_\mathrm{on}\) and start_xmit events. Figure 5.2 (right) shows that the card starts transmitting always in the same instant whenever the kernel triggers the transmission within the first 250 \(\mu\)s right after the \(t_\mathrm{on}\) event (lines 0 and 200). Otherwise, the card starts transmitting almost instantaneously (line 350). This experiments demonstrate that the device needs \(\Delta t_\mathrm{ready} = 200\) \(\mu\)s to get ready to transmit/receive after returning to idle.
Summing up, our experiments show that, if we want to bring this card to sleep during a certain time \(\Delta t_\mathrm{sleep}\), we should take into account that it requires a minimum sleep time \(\Delta t_\mathrm{sleep,min}=300\) \(\mu\)s. Therefore, \(\Delta t_\mathrm{sleep} \geq \Delta t_\mathrm{sleep,min}\) must be satisfied, and we must program the \(t_\mathrm{on}\) interrupt to be triggered \(\Delta t_\mathrm{on} + \Delta t_\mathrm{ready}=250\) \(\mu\)s before the end of the sleep. Note also that the card wastes a fixed time \(\Delta t_\mathrm{waste}\) consuming \(P_\mathrm{idle}\):
\[\begin{equation} \Delta t_\mathrm{waste} = \Delta t_\mathrm{off} + \Delta t_\mathrm{ready} \tag{5.4} \end{equation}\]
which is equal to 250 \(\mu\)s also. Thus, the total time in sleep state is \(\Delta t_\mathrm{sleep} - \Delta t_\mathrm{waste}\), and the energy toll from Equation (5.2) can be simplified as follows:
\[\begin{equation} E_\mathrm{waste} \approx (P_\mathrm{idle} - P_\mathrm{sleep})\cdot\Delta t_\mathrm{waste} \tag{5.5} \end{equation}\]
5.2 Protocol Analysis and Practical Issues
The key idea of this chapter is to put the interface to sleep during packet overhearing while meeting the constraint \(\Delta t_\mathrm{sleep,min}\) identified in the previous section. Additionally, such a mechanism should be local in order to be incrementally deployable, standard-compliant, and should take into account real-world practical issues. For this purpose, we first identify potential micro-sleep opportunities in 802.11, and explore well-known practical issues of WLAN networks that had not been addressed by previous energy-saving schemes.
5.2.1 Identifying Potential Micro-Sleep Opportunities
Due to the CSMA mechanism, an 802.11 station (STA) receives every single frame from its Service Set Identifier (SSID) or from others in the same channel (even some frames from overlapping channels). Upon receiving a frame, a STA checks the Frame Check Sequence (FCS) for errors and then, and only after having received the entire frame, it discards the frame if it is not the recipient. In 802.11 terminology, this is called packet overhearing. Since packet overhearing consumes the power corresponding to a full packet reception that is not intended for the station, it represents a source of inefficiency. Thus, we could avoid this unnecessary power consumption by triggering micro-sleeps that bring the wireless card to a low-energy state.
Indeed, the Physical Layer Convergence Procedure (PLCP) carries the necessary information (rate and length) to know the duration of the PLCP Service Data Unit (PSDU), which consists of a MAC frame or an aggregate of frames. And the first 10 bytes of a MAC frame indicate the intended receiver, so a frame could be discarded very early, and the station could be brought to sleep if the hardware allows for such a short sleeping time. Therefore, the most naive micro-sleep mechanism could determine, given the constraint \(\Delta t_\mathrm{sleep,min}\), whether the interface could be switched off in a frame-by-frame basis. And additionally, this behaviour can be further improved by leveraging the 802.11 virtual carrier-sensing mechanism.
Virtual carrier-sensing allows STAs not only to seize the channel for a single transmission, but also to signal a longer exchange with another STA. For instance, this exchange can include the acknowledgement sent by the receiver, or multiple frames from a station in a single transmission opportunity (TXOP). MAC frames carry a duration value that updates the Network Allocation Vector (NAV), which is a counter indicating how much time the channel will be busy due to the exchange of frames triggered by the current frame. This duration field is, for our benefit, enclosed in the first 10 bytes of the MAC header too. Therefore, the NAV could be exploited to obtain substantial gains in terms of energy.
In order to unveil potential sleeping opportunities within the different states of operation in 802.11, first of all we review the setting of the NAV. 802.11 comprises two families of channel access methods. Within the legacy methods, the Distributed Coordination Function (DCF) is the basic mechanism with which all STAs contend employing CMSA/CA with binary exponential backoff. In this scheme, the duration value provides single protection: the setting of the NAV value is such that protects up to the end of one frame (data, management) plus any additional overhead (control frames)37.
When the Point Coordination Function (PCF) is used, time between beacons is rigidly divided into contention and contention-free periods (CP and CFP, respectively). The AP starts the CFP by setting the duration value in the beacon to its maximum value38. Then, it coordinates the communication by sending CF-Poll frames to each STA. As a consequence, a STA cannot use the NAV to sleep during the CFP, because it must remain CF-pollable, but it still can doze during each individual packet transmission. In the CP, DCF is used.
802.11e introduces traffic categories (TC), the concept of TXOP, and a new family of access methods called Hybrid Coordination Function (HCF), which includes the Enhanced Distributed Channel Access (EDCA) and the HCF Controlled Channel Access (HCCA). These two methods are the QoS-aware versions of DCF and PCF respectively.
Under EDCA, there are two classes of duration values: single protection, as in DCF, and multiple protection, where the NAV protects up to the end of a sequence of frames within the same TXOP. By setting the appropriate TC, any STA may start a TXOP, which is zero for background and best-effort traffic, and of several milliseconds for video and audio traffic as defined in the standard39. A non-zero TXOP may be used for dozing, as 11ac does, but these are long sleeps and the AP needs to support this feature, because a TXOP may be truncated at any moment with a CF-End frame, and it must keep buffering any frame directed to any 11ac dozing STA until the NAV set at the start of the TXOP has expired.
HCCA works similarly to PCF, but under HCCA, the CFP can be started at almost any time. In the CFP, when the AP sends a CF-poll to a STA, it sets the NAV of other STAs for an amount equal to the TXOP. Nevertheless, the AP may reclaim the TXOP if it ends too early (e.g., the STA has nothing to transmit) by resetting the NAV of other STAs with another CF-Poll. Again, the NAV cannot be locally exploited to perform energy saving during a CFP.
Finally, there is another special case in which the NAV cannot be exploited either. 802.11g was designed to bring the advantages of 11a to the 2.4 GHz band. In order to interoperate with older 11b deployments, it introduces CTS-to-self frames (also used by more recent amendments such as 11n and 11ac). These are standard CTS frames, transmitted at a legacy rate and not preceded by an RTS, that are sent by a certain STA to itself to seize the channel before sending a data frame. In this case, the other STAs cannot know which will be the destination of the next frame. Therefore, they should not use the duration field of a CTS for dozing.
5.2.2 Impact of Capture Effect
It is well-known that a high-power transmission can totally blind another one with a lower SNR. Theoretically, two STAs seizing the channel at the same time yields a collision. However, in practice, if the power ratio is sufficiently high, a wireless card is able to decode the high-power frame without error, thus ignoring the other transmission. This is called capture effect, and although not described by the standard, it must be taken into account as it is present in real deployments.
According to Lee et al. (2007), there are two types of capture effect depending on the order of the frames: if the high-power frame comes first, it is called first capture effect; otherwise, it is called second capture effect. The first one is equivalent to receiving a frame and some noise after it, and then it has no impact in our analysis. In the second capture effect, the receiving STA stops decoding the PLCP of the low-power frame and switches to another with higher power. If the latter arrives before a power-saving mechanism makes the decision to go to sleep, the mechanism introduces no misbehaviour.
However, Lee et al. (2007) suggests that a high-power transmission could blind a low-power one at any time, even when the actual data transmission has begun. This is called Message in Message (MIM) in the literature (Santhapuri et al. 2008; Wang, Leong, and Leong 2014), and it could negatively impact the performance of an interface implementing an energy-efficiency mechanism based on packet overhearing. In the following, we will provide new experimental evidence supporting that this issue still holds in modern wireless cards.
We evaluated the properties of the MIM effect with an experimental setup consisting of a card under test, a brand new 802.11ac three-stream Qualcomm Atheros QCA988x card, and three additional helper nodes. These are equipped with Broadcom KBFG4318 802.11g cards, whose behaviour can be changed with the open-source firmware OpenFWWF (Gringoli and Nava 2015). We disable the carrier sensing and back-off mechanisms so that we can decide the departure time of every transmitted frame with 1 \(\mu\)s granularity with respect to the internal 1MHz clock.
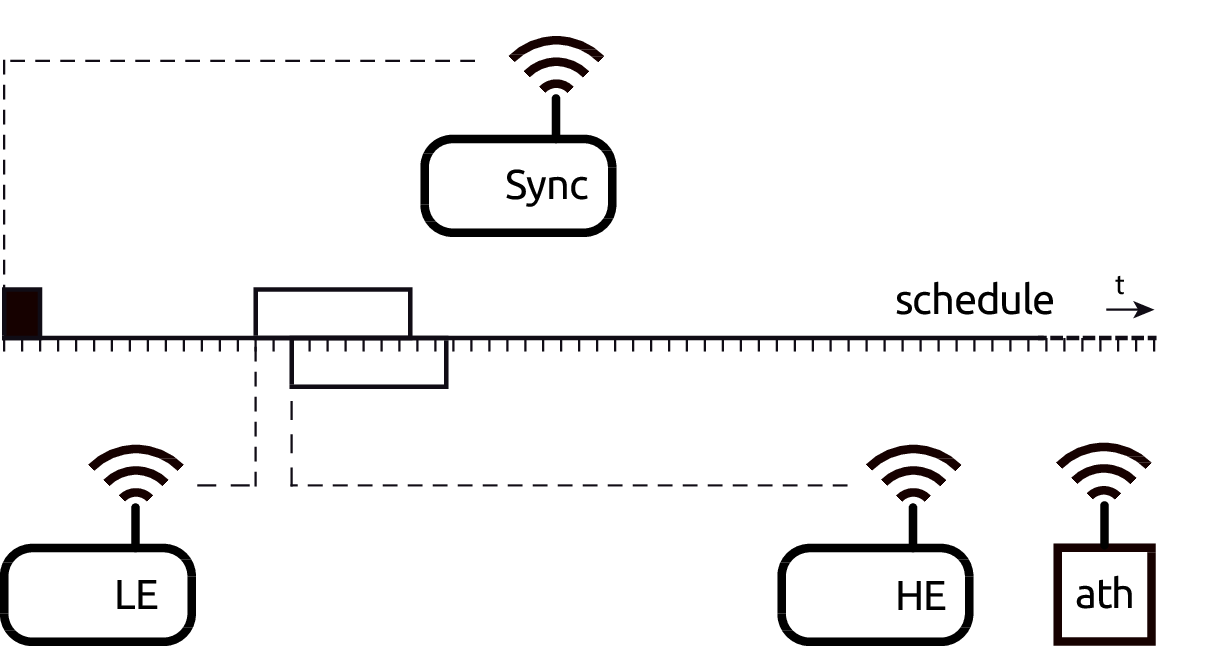
Figure 5.3: Measurement setup for the MIM effect.
Figure 5.3 depicts the measurement setup, which consists of a node equipped with our Atheros card under test (ath), a synchronization (Sync) node, a high energy (HE) node and a low energy (LE) node. These two HE and LE nodes were manually carried around at different distances with respect to the ath node until we reached the desired power levels.
The Sync node transmits 80-byte long beacon-like frames periodically at 48 Mbps, one beacon every 8192 \(\mu\)s: the time among consecutive beacons is divided in 8 schedules of 1024 \(\mu\)s. Inside each schedule, time is additionally divided into 64 micro-slots of 16 \(\mu\)s. We then program the firmware of the HE and LE nodes to use the beacon-like frames for keeping their clocks synchronised and to transmit a single frame (138-\(\mu\)s long) per schedule starting at a specific micro-slot. This allows us to always start the transmission of the low energy frame from the LE node before the high energy frame from the HE node, and to configure the exact delay \(\Delta t\) as a multiple of the micro-slot duration.
For instance, we set up a \(\Delta t = 32\) \(\mu\)s by configuring LE node to transmit at slot 15, HE node at slot 17. By moving LE node away from the ath node while the HE node is always close, we are able to control the relative power difference \(\Delta P\) received by the ath node between frames coming from the LE and HE nodes. With the configured timings, we are able to replicate the reception experiment at the ath node approximately 976 times per second, thus collecting meaningful statistics in seconds.
| \(\Delta P\) [dB] | \(\Delta t\) [\(\mu\)s] | \(\%\) rx | \(\%\) err | \(\%\) rx | \(\%\) err |
|---|---|---|---|---|---|
| \(\leq\) 5 | 0 | 0.04 | 50.00 | 92.00 | 17.67 |
| 16 | 0.40 | 0.00 | 2.15 | 0.00 | |
| 32 | 99.32 | 99.96 | 0.24 | 0.00 | |
| \(\geq\) 48 | 99.10 | 99.75 | 0.34 | 0.00 | |
| \(\geq\) 144 | 98.94 | 0.00 | 97.32 | 0.00 | |
| \(\geq\) 35 | 0 | 0.18 | 0.00 | 99.37 | 0.00 |
| 16 | 0.37 | 1.11 | 91.87 | 0.00 | |
| 32 | 0.39 | 78.95 | 89.89 | 0.00 | |
| 48 | 1.54 | 68.00 | 95.58 | 0.00 | |
| 64 | 3.22 | 98.73 | 89.83 | 0.00 | |
| 128 | 60.35 | 99.96 | 39.24 | 0.00 | |
| \(\geq\) 144 | 95.33 | 0.00 | 99.64 | 0.00 |
We obtained the results shown in Table 5.1. When the energy gap is small (\(\le\) 5 dB), the MIM effect never enters into play as we can see from the first part of Table 5.1. If the two frames are transmitted at the same time, then the QCA card receives the majority of the HE frames (92%) despite some of them are broken (17%); almost no LE frames are received. By increasing the delay to 16 \(\mu\)s, the QCA card stops working: the short delay means that the HE frame collide with the LE one at the PLCP level. The energy gap does not allow the QCA correlator to restart decoding a new PLCP and, in fact, only a few frames are sporadically received. Further increasing the delay allows the QCA card to correctly receive the PLCP preamble of the LE frame, but then the PDU decoding is affected by errors (e.g., delay set to 48 \(\mu\)s) because of collision. Finally, if the delay is high enough so that both frames fit into a schedule, the QCA card receives everything correctly (\(\ge\) 144 \(\mu\)s).
When the energy gap exceeds a threshold (i.e., more than 35 dB), then the behaviour of the QCA card changes radically as we can see from the second part of Table 5.1: first, with no delay, all high energy frames are received (expected given that they overkill the others); second, when both frame types fit in the schedule, all of them are received, which confirms that the link between LE node and the QCA is still very good. But, unlike the previous case, HE frames are received regardless of the delay, which means that the correlator restarts decoding the PLCP of the second frame because of the higher energy, enough for distinguishing it from the first frame that simply turns into a negligible noise.
Thus, our experiments confirm that the MIM effect actually affects modern wireless cards, and therefore it should be taken into account in any micro-sleep strategy. Let us consider, for instance, a common infrastructure-based scenario in which certain STA receives low-power frames from a distant network in the same channel. If the AP does not see them, we are facing the hidden node problem. It is clear that none of these frames will be addressed to our STA, but, if it goes to sleep during these transmissions, it may lose potential high-power frames from its BSSID. Therefore, if we perform micro-sleeps under hidden node conditions, in some cases we may lose frames that we would receive otherwise thanks to the capture effect. The same situation may happen within the local BSSID (the low-power frames belong to the same network), but this is far more rare, as such a hidden node will become disconnected sooner or later.
In order to circumvent these issues, a STA should only exploit micro-sleep opportunities arising from its own network. To discard packets originating from other networks, the algorithm looks at the BSSID in the receiver address within frames addressed to an AP. If the frame was sent by an AP, it only needs to read 6 additional bytes (in the worst case), which are included in the transmitter address. Even so, these additional bytes do not necessarily involve consuming more time, depending on the modulation. For instance, for OFDM 11ag rates, this leads to a time increase of 8 \(\mu\)s at 6 and 9 Mbps, 4 \(\mu\)s at 12, 18 and 36 Mbps, and no time increase at 24, 48 and 54 Mbps.
5.2.3 Impact of Errors in the MAC Header
Taking decisions without checking the FCS (placed at the end of the frame) for errors or adding any protection mechanism may lead to performance degradation due to frame loss. This problem was firstly identified by Balaji, Tamma, and Manoj (2010) and Prasad et al. (2014) which, based on purely qualitative criteria, reached opposite conclusions. The first work advocates for the need for a new CRC to protect the header bits while the latter dismisses this need. This section is devoted to analyse quantitatively the impact of errors.
At a first stage, we need to identify, field by field, which cases are capable of harming the performance of our algorithm due to frame loss. The duration/ID field (2 bytes) and the MAC addresses (6 bytes each) are an integral part of our algorithm. According to its encoding, the duration/ID field will be interpreted as an actual duration if and only if the bit 15 is equal to 0. Given that the bit 15 is the most significant one, this condition is equivalent to the value being smaller than 32 768. Therefore, we can distinguish the following cases in terms of the possible errors:
- An error changes the bit 15 from 0 to 1. The field will not be interpreted as a duration and hence we will not go to sleep. We will be missing an opportunity to save energy, but there will be no frame loss and, therefore, the network performance will not be affected.
- An error changes the bit 15 from 1 to 0. The field will be wrongly interpreted as a duration. The resulting sleep will be up to 33 ms longer than required, with the potential frame loss associated.
- With the bit 15 equal to 0, an error affects the previous bits. The resulting sleep will be shorter or longer that the real one. In the first case, we will be missing an opportunity to save energy; in the second case, there is again a potential frame loss.
Regarding the receiver address field, there exist the following potential issues:
- A multicast address changes but remains multicast. The frame will be received and discarded, i.e., the behaviour will be the same as with no error. Hence, it does not affect.
- A unicast address changes to multicast. The frame will be received and discarded after detecting the error. If the unicast frame was addressed to this host, it does not affect. If it was addressed to another host, we will be missing an opportunity to save energy.
- A multicast address changes to unicast. If the unicast frame is addressed to this host, it does not affect. If it is addressed to another host, we will save energy with a frame which would be otherwise received and discarded.
- Another host’s unicast address changes to your own. This case is very unlikely. The frame will be received and discarded, so we will be missing an opportunity to save energy.
- Your own unicast address changes to another’s. We will save energy with a frame otherwise received and discarded.
As for the transmission address field, this is checked as an additional protection against the undesirable effects of the already discussed intra-frame capture effect. If the local BSSID in a packet changes to another BSSID, we will be missing an opportunity to save energy. It is extremely unlikely that an error in this field could lead to frame loss: a frame from a foreign node (belonging to another BSSID and hidden to our AP) should contain an error that matches the local BSSID in the precise moment in which our AP tries to send us a frame40.
Henceforth, we draw the following conclusions:
- Errors at the MAC addresses do not produce frame loss, because under no circumstances they imply frame loss. The only impact is that there will be several new opportunities to save energy and several others will be wasted.
- Errors at the duration/ID field, however, may produce frame loss due to frame loss in periods of time up to 33 ms. Also several energy-saving opportunities may be missed without yielding any frame loss.
- An error burst affecting both the duration/ID field and the receiver address may potentially change the latter in a way that the frame would be received (multicast bit set to 1) and discarded, and thus preventing the frame loss.
From the above, we have that the only case that may yield performance degradation in terms of frame loss is when we have errors in the duration/ID field. In the following, we are going to analytically study and quantify the probability of frame loss in this case. For our analysis, we first consider statistically independent single-bit errors. Each bit is considered the outcome of a Bernoulli trial with a success probability equal to the bit error probability \(p_{b}\). Thus, the number of bit errors, \(X\), in certain field is given by a Binomial distribution \(X\sim \operatorname{B}(N, p_b)\), where \(N\) is the length of that field.
With these assumptions, we can compute the probability of having more than one erroneous bit, \(\Pr(X \geq 2)\), which is three-four orders of magnitude smaller than \(p_b\) with realistic \(p_b\) values. Therefore, we assume that we never have more than one bit error in the frame header, so the probability of receiving an erroneous duration value with a single-bit error, \(p_{e,b}\), is the following:
\[\begin{equation} p_{e,b} \approx 1 - (1 - p_b)^{15} \tag{5.6} \end{equation}\]
However, not all the errors imply a duration value greater than the original one, but only those which convert a zero into a one. Let us call \(\operatorname{Hw}(i)\) the Hamming weight, i.e., the number of ones in the binary representation of the integer \(i\). The probability of an erroneous duration value greater than the original, \(p_{eg,b}\), is the following:
\[\begin{equation} p_{eg,b}(i) = p_{e,b}\cdot \frac{15 -\operatorname{Hw}(i)}{15} \tag{5.7} \end{equation}\]
which represents a fraction of the probability \(p_{e,b}\) and depends on the original duration \(i\) (before the error).
In order to understand the implications of the above analysis in real networks, we have analysed the SIGCOMM’08 data set (Schulman, Levin, and Spring 2009) and gathered which duration values are the most common. In the light of the results depicted in Table 5.2, it seems reasonable to approximate \(p_{eg,b}/p_{e,b} \approx 1\), because it is very likely that the resulting duration will be greater than the original.
| Duration | \(\%\) | \(p_{eg,b}/p_b\) | Cause |
|---|---|---|---|
| 44 | 62.17 | 0.88 | SIFS + ACK at 24 Mbps |
| 0 | 25.23 | 1.00 | Broadcast, multicast frames |
| 60 | 6.54 | 0.73 | SIFS + ACK at 6 Mbps |
| 48 | 5.82 | 0.87 | SIFS + ACK at 12 Mbps |
Finally, we can approximate \(p_b\) by the BER and, based on the above data and considerations, the frame loss probability, \(p_{\mathrm{loss}}\), due to an excessive sleep interval using a single-bit error model is the following:
\[\begin{equation} p_{\mathrm{loss}} = p_{eg,b} \approx p_{e,b} \approx 1 - (1 - \mathrm{BER})^{15} \tag{5.8} \end{equation}\]
This analysis assumes independent errors. However, it is well known that errors typically occur in bursts. In order to understand the impact of error bursts in our scheme, we analyse a scenario with independent error bursts of length \(X\) bits, where \(X\) is a random variable. To this end, we use the Neyman-A contagious model (Neyman 1939), which has been successfully applied in telecommunications to describe burst error distributions41. This model assumes that both the bursts and the burst length are Poisson-distributed. Although assuming independency between errors in the same burst may not be accurate, it has been shown that the Neyman-A model performs well for short intervals (Cornaglia and Spini 1996), which is our case.
The probability of having \(k\) errors in an interval of \(N\) bits, given the Neyman-A model, is the following:
\[\begin{equation} p_N(k) = \frac{\lambda_b^k}{k!}e^{-\lambda_B}\sum_{i=0}^\infty\frac{i^k}{i!}\lambda_B^i e^{-i\lambda_b} \tag{5.9} \end{equation}\]
where
- \(\lambda_b\)
- is the average number of bits in a burst.
- \(\lambda_B\)
- \(= Np_b/\lambda_b\) is the average number of bursts.
This can be transformed into a recursive formula with finite sums:
\[\begin{equation} \begin{split} p_N(k) &= \frac{\lambda_B\lambda_b e^{-\lambda_b}}{k}\sum_{j=0}^{k-1} \frac{\lambda_b^j}{j!}p_N(k-1-j) \\ p_N(0) &= e^{-\lambda_B\left(1-e^{-\lambda_b}\right)} \end{split} \tag{5.10} \end{equation}\]
Following the same reasoning as for the single-bit case, we can assume one burst at a time which will convert the duration value into a higher one. Then, the frame loss probability is the following:
\[\begin{equation} p_{\mathrm{loss}} = \sum_{k=1}^{15} p_{15}(k) \tag{5.11} \end{equation}\]
with parameters \(\lambda_b\) and \(p_b \approx \mathrm{BER}\).
Figure 5.4 evaluates both error models as a function of BER. As expected, the single-bit error model is an upper bound for the error burst model and represents a worst-case scenario. At most, the frame loss probability is one order of magnitude higher than BER. Therefore, we conclude that the frame loss is negligible for reasonable BERs and, consequently, the limited benefit of an additional CRC does not compensate the issues.
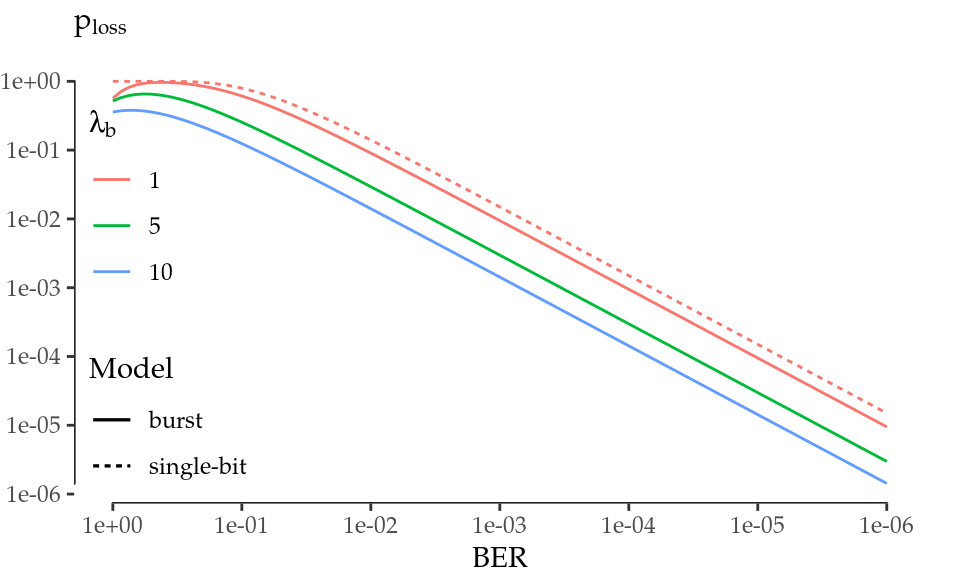
Figure 5.4: Frame loss probability given a BER level.
5.3 \(\mu\)Nap Algorithm
In the following, we present \(\mu\)Nap, which builds upon the insights provided in previous sections and tries to save energy during the channel transmissions in which the STA is not involved. However, not all transmissions addressed to other stations are eligible for dozing, as the practical issues derived from the capture effect may incur in performance degradation. Therefore, the algorithm must check both the receiver as well as the transmitter address in the MAC header in order to determine whether the incoming frame is addressed to another station and it comes from within the same network.
If these conditions are met, a basic micro-sleep will last the duration of the rest of the incoming frame plus an inter-frame space (SIFS). Unfortunately, the long times required to bring an interface back and forth from sleep, as discovered in Section 5.1, shows that this basic micro-sleep may not be long enough to be exploitable. Thus, the algorithm should take advantage of the NAV field whenever possible. Our previous analysis shows that this duration information stored in the NAV is not exploitable in every circumstance: the interface can leverage this additional time during CPs and it must avoid any NAV set by a CTS packet.
Finally, after a micro-sleep, two possible situations arise:
- The card wakes up at the end of a frame exchange. For instance, after a data + ACK exchange. In this case, all STAs should wait for a DIFS interval before contending again.
- The card wakes up in the middle of a frame exchange. For instance, see Figure 5.5, where an RTS/CTS-based fragmented transmission is depicted.
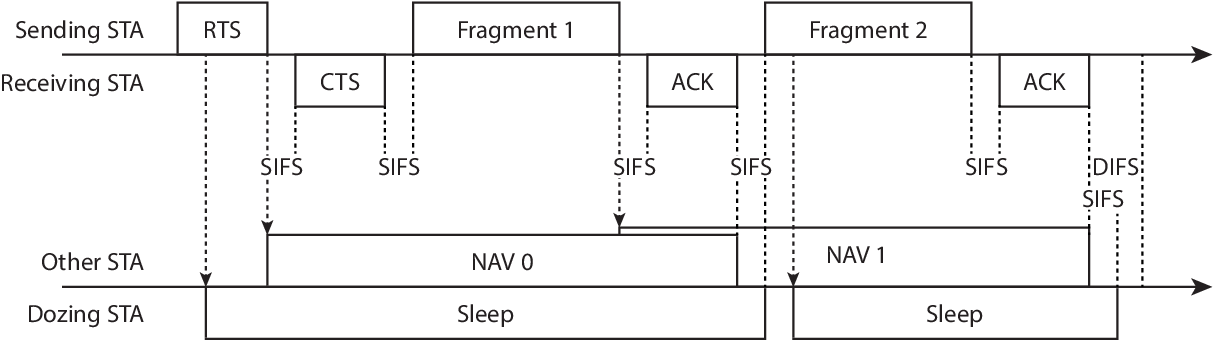
Figure 5.5: RTS/CTS-based fragmented transmission example and \(\mu\)Nap’s behaviour.
In the latter example, an RTS sets the NAV to the end of a fragment, and our algorithm triggers the sleep. This first fragment sets the NAV to the end of the second fragment, but it is not seen by the dozing STA. When the latter wakes up, it sees a SIFS period of silence and then the second fragment, which sets its NAV again and may trigger another sleep. This implies that the STA can doze for an additional SIFS, as Figure 5.5 shows, and wait in idle state until a DIFS is completed before trying to contend again.
Based on the above, Algorithm 5.6 describes the main loop of a wireless card’s microcontroller that would implement our mechanism. When the first 16 bytes of the incoming frame are received, all the information needed to take the decision is available: the duration value (\(\Delta t_\mathrm{NAV}\)), the receiver address (\(R_A\)) and the transmitter address (\(T_A\)). The ability to stop a frame’s reception at any point has been demonstrated to be feasible (Berger et al. 2014). Note that MAC addresses can be efficiently compared in a streamed way, so that the first differing byte (if the first byte of the \(R_A\) has the multicast bit set to zero, i.e., \(R_A\) is unicast) triggers our sleep procedure (Set_Sleep in Algorithm 5.6). In addition, the main loop should keep up to date a global variable (\(C\)) indicating whether the contention is currently allowed (CP) or not (CFP). This is straightforward, as every CFP starts and finishes with a beacon frame.

Figure 5.6: \(\mu\)Nap implementation. Main loop modification to leverage micro-sleeps.
The Set_Sleep procedure takes as input the remaining time until the end of the incoming frame (\(\Delta t_\mathrm{DATA}\)) and the duration value (\(\Delta t_\mathrm{NAV}\)). The latter is used only if it is a valid duration value and a CP is active. Then, the card may doze during \(\Delta t_\mathrm{sleep}\) (if this period is greater than \(\Delta t_\mathrm{sleep,min}\)), wait for a DIFS to complete and return to the main loop.
Finally, it is worth noting that this algorithm is deterministic, as it is based on a set of conditions to trigger the sleep procedure. It works locally with the information already available in the protocol headers, without incurring in any additional control overhead and without impacting the normal operation of 802.11. Specifically, our analytical study of the impact of errors in the first 16 bytes of the MAC header shows that the probability of performance degradation is comparable to the BER under normal channel conditions. Therefore, the overall performance in terms of throughput and delay is completely equivalent to normal 802.11.
5.4 Performance Evaluation
This section is devoted to evaluate the performance of \(\mu\)Nap. First, through trace-driven simulation, we show that \(\mu\)Nap significantly reduces the overhearing time and the energy consumption in a real network. Secondly, we analyse the impact of the timing constraints imposed by the hardware, which are specially bad in the case of the AR9280, and we discuss the applicability of \(\mu\)Nap in terms of those parameters and the evolution trends in the 802.11 standard.
5.4.1 Evaluation with Real Traces
In the following, we conduct an evaluation to assess how much energy might be saved in a real network if all STAs implement \(\mu\)Nap using the AR9280. The reasons for this are twofold. On the one hand, the timing properties of this interface are particularly bad if we think of typical frame durations in 802.11, which means that many micro-sleep opportunities will be lost due to hardware constraints. On the other hand, it does not support newer standards that could potentially lead to longer micro-sleep opportunities through mechanisms such as frame aggregation. Therefore, an evaluation based on an 11a/g network and the AR9280 chip represents a worst case scenario for our algorithm.
For this purpose, we used 802.11a wireless traces with about 44 million packets, divided in 43 files, from the SIGCOMM’08 data set (Schulman, Levin, and Spring 2009). The methodology followed to parse each trace file is as follows. Firstly, we discover all the STAs and APs present. Each STA is mapped into its BSSID and a bit array is developed in order to hold the status at each point in time (online or offline). It is hard to say when a certain STA is offline from a capture, because they almost always disappear without sending a disassociation frame. Thus, we use the default rule in hostapd, the daemon that implements the AP functionality in Linux: a STA is considered online if it transmitted a frame within the last 5 min.
Secondly, we measure the amount of time that each STA spends (without our algorithm) in the following states: transmission, reception, overhearing and idle. We consider that online STAs are always awake; i.e., even if a STA announces that it is going into PS mode, we ignore this announcement. We measure also the amount of time that each STA would spend (with our algorithm) in transmission, reception, overhearing, sleep and idle. Transmission and reception times match the previous case, as expected. As part of idle time, we account separately the wasted time in each micro-sleep as a consequence of hardware limitations (the fixed toll \(\Delta t_\mathrm{waste}\)). After this processing, there are a lot of duplicate unique identifiers (MAC addresses), i.e., STAs appearing in more than one trace file. Those entries are summarised by aggregating the time within each state.
At this point, let us define the activity time as the sum of transmission, reception, overhearing, sleep and wasted time. We do not take into account the idle time since our goal is to understand how much power we can save in the periods of activity, which are the only ones that consume power in wireless transmissions (the scope of our mechanism). Using the definition above, we found that the majority of STAs reveals very little activity (they are connected for a few seconds and disappear). Therefore, we took the upper decile in terms of activity, thus obtaining the 42 more active STAs.
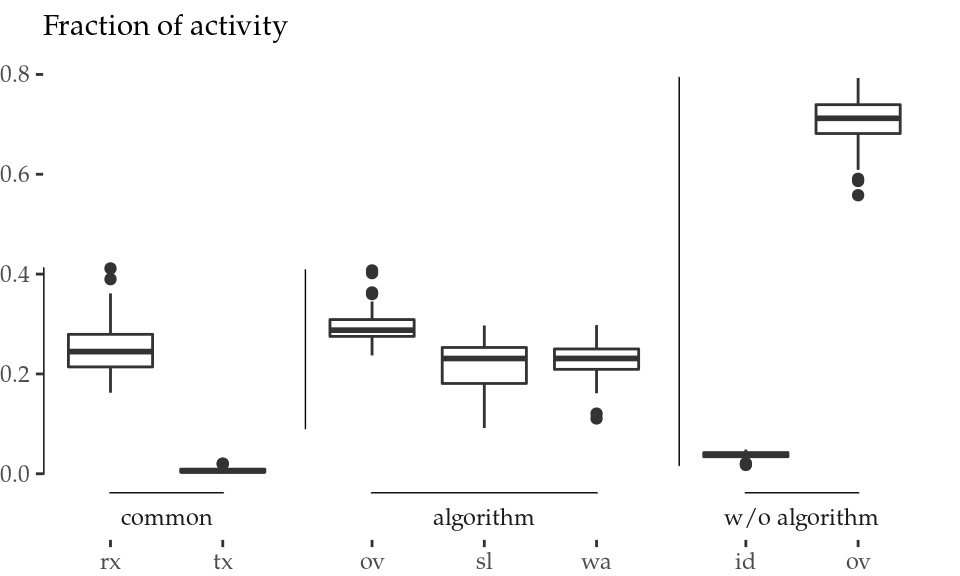
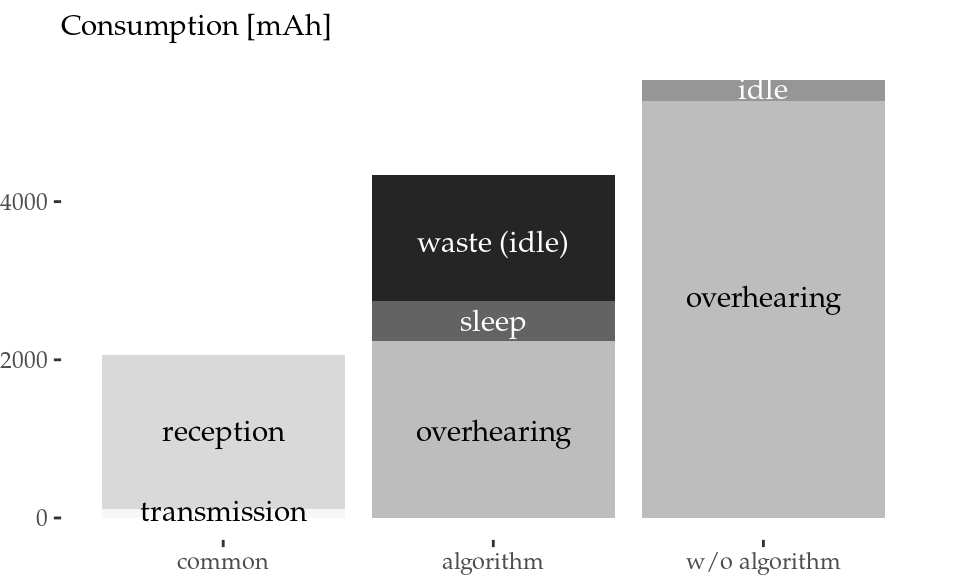
Figure 5.7: Normalised activity aggregation (left) and energy consumption aggregation (right) of all STAs.
The activity aggregation of all STAs is normalised and represented in Figure 5.7 (left). Transmission (tx) and reception (rx) times are labelled as common, because STAs spend the same time transmitting and receiving both with and without our algorithm. It is clear that our mechanism effectively reduces the total overhearing (ov) time from a median of 70% to a 30% approximately (a 57% reduction). The card spends consistently less time in overhearing because this overhearing time difference, along with some idle (id) time from inter-frame spaces, turns into micro-sleeps, that is, sleep (sl) and wasted (wa) time.
This activity aggregation enables us to calculate the total energy consumption using the power values from the thorough characterisation presented in Section 3.4.1. Figure 5.7 (right) depicts the energy consumption in units of mAh (assuming a typical 3.7-V battery). The energy savings overcome 1200 mAh even with the timing limitations of the AR9280 card, which (i) prevents the card from going to sleep when the overhearing time is not sufficiently long, and (ii) wastes a long fixed time in idle during each successful micro-sleep. This reduction amounts to a 21.4% of the energy spent in overhearing and a 15.8% of the total energy during the activity time, when the transmission and reception contributions are also considered.
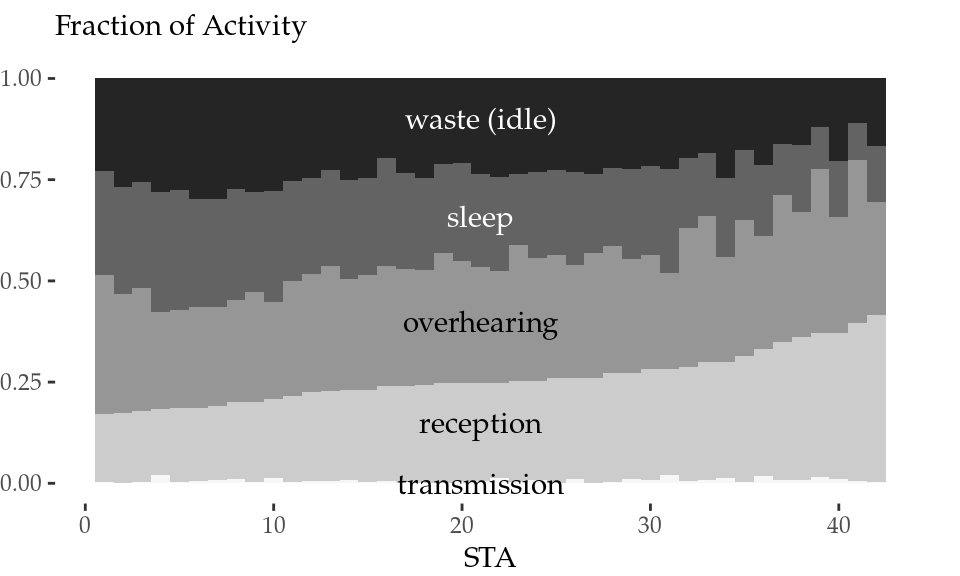
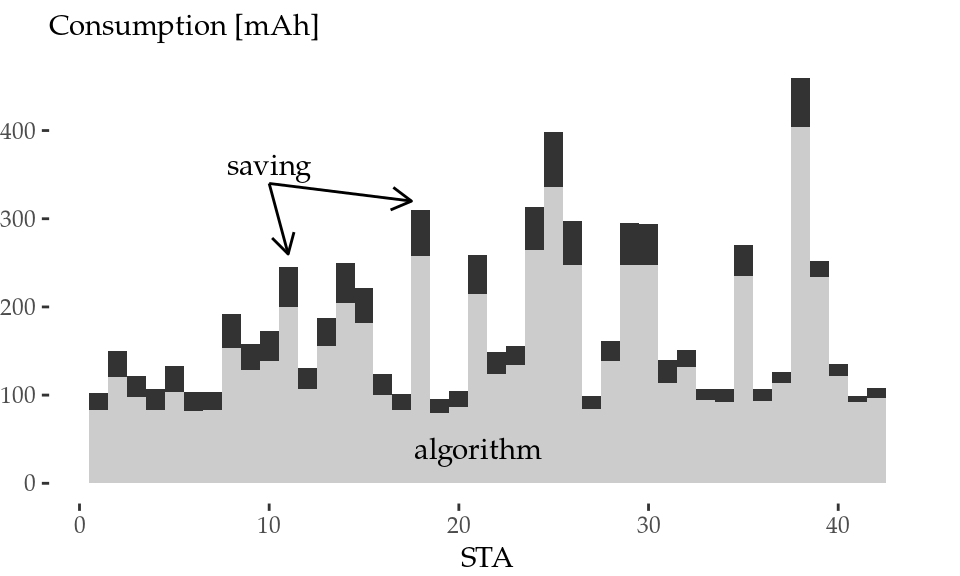
Figure 5.8: Normalised activity (left) and energy consumption (right) per STA.
Figure 5.8 provides a breakdown of the data by STA. The lower graph shows the activity breakdown per STA for our algorithm (transmission bars, in white, are very small). Overhearing time is reduced to a more or less constant fraction for all STAs (i.e., with the algorithm, the overhearing bars represent more or less a 30% of the total activity for all STAs), while less participative STAs (left part of the graph) spend more time sleeping. The upper graph shows the energy consumption per STA with our algorithm along with the energy-saving in dark gray, which is in the order of tens of mAh per STA.
5.4.2 Impact of Timing Constraints
The performance gains of \(\mu\)Nap depend on the behaviour of the circuitry. Its capabilities, in terms of timing, determine the maximum savings that can be achieved. Particularly, each micro-sleep has an efficiency (in comparison to an ideal scheme in which the card stays in sleep state over the entire duration of the micro-sleep) given by
\[\begin{equation} \frac{E'_\mathrm{save}}{E_\mathrm{save}} = \frac{E_\mathrm{save} - E_\mathrm{waste}}{E_\mathrm{save}} \approx 1 - \frac{\Delta t_\mathrm{waste}}{\Delta t_\mathrm{sleep}} \tag{5.12} \end{equation}\]
which results from the combination of Equations (5.1), (5.2) and (5.5).
Figure 5.9 represents this sleep efficiency for the AR9280 card (\(\Delta t_\mathrm{waste}=250\)) along with other values. It is clear that an improvement of \(\Delta t_\mathrm{waste}\) is fundamental to boost performance in short sleeps.
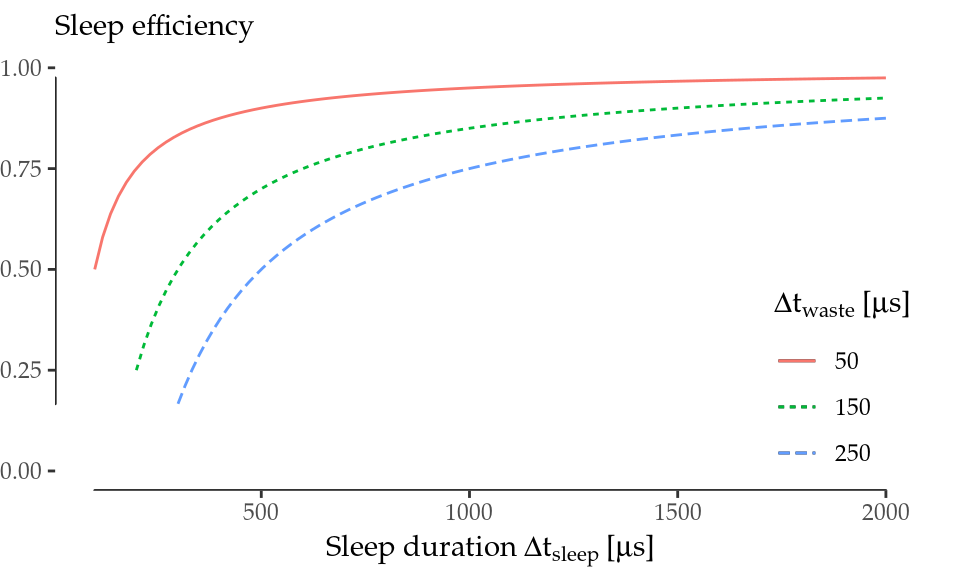
Figure 5.9: Sleep efficiency \(E'_\mathrm{save}/E_\mathrm{save}\) as \(\Delta t_\mathrm{waste}\) decreases.
Similarly, the constraint \(\Delta t_\mathrm{sleep,min}\) limits the applicability of \(\mu\)Nap, especially in those cases where the NAV cannot be used to extend the micro-sleep. For instance, let us consider the more common case in 11a/b/g networks: the transmission of a frame (up to 1500 bytes long) plus the corresponding ACK. Then,
\[\begin{equation} \Delta t_\mathrm{sleep,min} \le \Delta t_\mathrm{DATA} + \Delta t_\mathrm{SIFS} + \Delta t_\mathrm{ACK} + \Delta t_\mathrm{SIFS} \tag{5.13} \end{equation}\]
and expanding the right side of the inequality,
\[\begin{equation*} \Delta t_\mathrm{sleep,min} \le \frac{8(14+l_\mathrm{min}+4)}{\lambda_\mathrm{DATA}} + \Delta t_\mathrm{PLCP} + \frac{8(14+2)}{\lambda_\mathrm{ACK}} + 2\Delta t_\mathrm{SIFS} \end{equation*}\]
Here, we can find \(l_\mathrm{min}\), which is the minimum amount of data (in bytes, and apart from the MAC header and the FCS) that a frame must contain in order to last \(\Delta t_\mathrm{sleep,min}\). Based on this \(l_\mathrm{min}\), Figure 5.10 defines the applicability in 802.11a DCF in terms of frame sizes (\(\le 1500\) bytes) that last \(\Delta t_\mathrm{sleep,min}\) at least. Again, an improvement in \(\Delta t_\mathrm{waste}\) would boost not only the energy saved per sleep, but also the general applicability defined in this way.
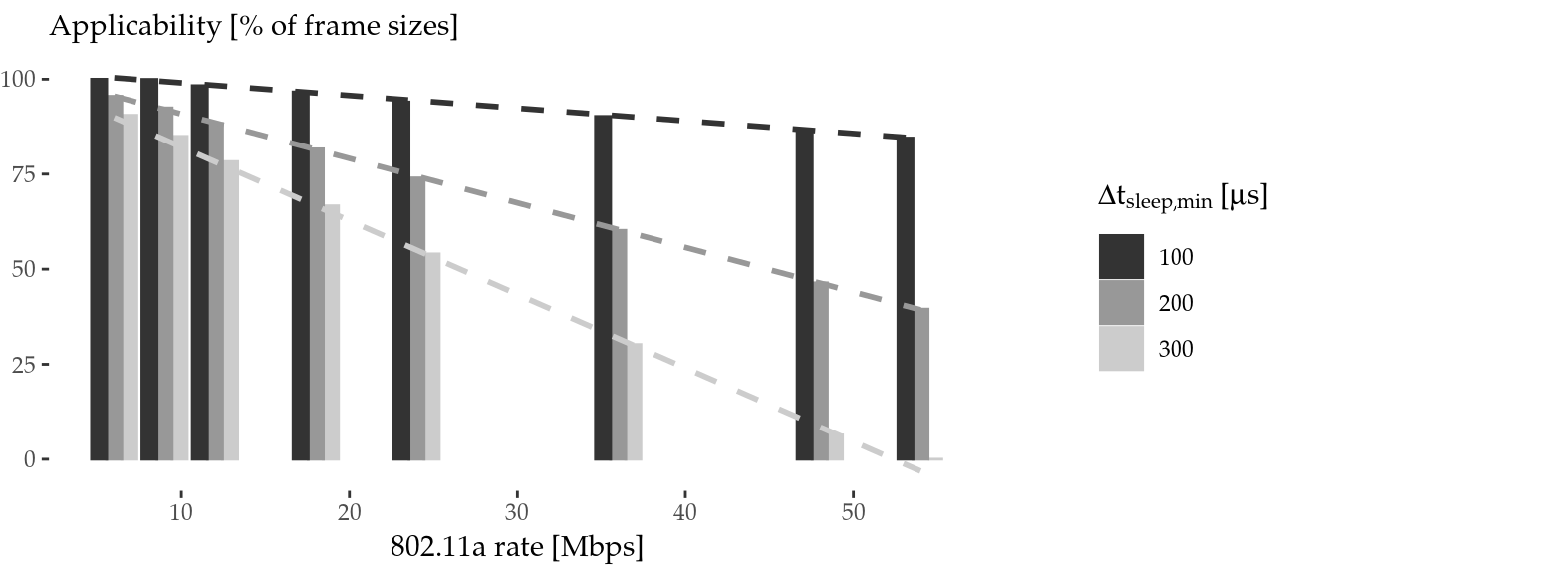
Figure 5.10: Algorithm applicability for common transmissions (\(\le 1500\) bytes \(+\) ACK) in 802.11a DCF mode.
The applicability of \(\mu\)Nap may also be affected by the evolution of the standard. Particularly, 802.11n introduced, and 802.11ac followed, a series of changes enabling high and very high throughput respectively, up to Gigabit in the latter case. This improvement is largely based on MIMO and channel binding: multiple spatial and frequency streams. Nevertheless, a single 20-MHz spatial stream is more or less equivalent to 11ag. Some enhancements (shorter guard interval and coding enhancements) may boost the throughput of a single stream from 54 to 72 Mbps under optimum conditions. Yet it is also the case that the PLCP is much longer to accommodate the complexity of the new modulation coding schemes (MCSs). This overhead not only extends each transmission, but also encourages the use of frame aggregation. Thus, the increasing bandwidth, in current amendments or future ones, does not necessarily imply a shorter airtime in practice, and our algorithm is still valid.
Reducing PHY’s timing requirements is essential to boost energy savings, but its feasibility should be further investigated. Nonetheless, there are some clues that suggest that there is plenty of room for improvement. In the first place, \(\Delta t_\mathrm{off}\) and \(\Delta t_\mathrm{on}\) should depend on the internal firmware implementation (i.e., the complexity of saving/restoring the state). Secondly, Figure 5.2 (left) indicates that a transmission is far more aggressive, in terms of a sudden power rise, than a return from sleep. From this standpoint, \(\Delta t_\mathrm{ready} = 200\) \(\mu\)s would be a pessimistic estimate of the time required by the circuitry to stabilise. Last, but not least, the 802.3 standard goes beyond 802.11 and, albeit to a limited extent, it defines some timing parameters42 of the PHYs, which are in the range of tens of \(\mu\)s in the worst case43.
Due to these reasons, WiFi card manufacturers should push for a better power consumption behaviour, which is necessary to boost performance with the power-saving mechanism presented in this paper. Furthermore, it is necessary for the standardisation committees and the manufacturers to collaborate to agree on power consumption behaviour guidelines for the hardware (similarly to what has been done with 802.3). Indeed, strict timing parameters would allow researchers and developers to design more advanced power-saving schemes.
5.5 Summary
Based on a thorough characterisation of the timing constraints and energy consumption of 802.11 interfaces, we have exhaustively analysed the micro-sleep opportunities that are available in current WLANs. We have unveiled the practical challenges of these opportunities, previously unnoticed in the literature, and, building on this knowledge, we have proposed \(\mu\)Nap (Azcorra et al. 2017, 2018) an energy-saving scheme that is orthogonal to the existing standard PS mechanisms. Unlike previous attempts, our scheme takes into account the non-zero time and energy required to move back and forth between the active and sleep states, and decides when to put the interface to sleep in order to make the most of these opportunities while avoiding frame losses.
We have demonstrated the feasibility of our approach using a robust methodology and high-precision instrumentation, showing that, despite the limitations of COTS hardware, the use of our scheme would result in a 57% reduction in the time spent in overhearing, thus leading to an energy saving of 15.8% of the activity time according to our trace-based simulation. Finally, based on these results, we have made the case for the strict specification of energy-related parameters of 802.11 hardware, which would enable the design of platform-agnostic energy-saving strategies.
References
Azcorra, Arturo, Iñaki Ucar, Albert Banchs, Francesco Gringoli, and Pablo Serrano. 2017. “\(\mu\)Nap: Practical micro-sleeps for 802.11 WLANs.” Computer Communications 110 (September): 175–86. https://doi.org/10.1016/j.comcom.2017.06.008.
Azcorra, Arturo, Iñaki Ucar, Albert Banchs, Francesco Gringoli, and Pablo Serrano. 2018. Energy-saving method based on micro-shutdowns for a wireless device in a telecommunications network, issued January 2018. http://www.google.com/patents/WO2018015601.
Balaji, Bharathan, Bheemarjuna Reddy Tamma, and B. S. Manoj. 2010. “A Novel Power Saving Strategy for Greening IEEE 802.11 Based Wireless Networks.” In 2010 Ieee Global Telecommunications Conference Globecom 2010, 1–5. IEEE. https://doi.org/10.1109/GLOCOM.2010.5684071.
Berger, Daniel S., Francesco Gringoli, Nicolò Facchi, Ivan Martinovic, and Jens Schmitt. 2014. “Gaining Insight on Friendly Jamming in a Real-World Ieee 802.11 Network.” In Proceedings of the 2014 Acm Conference on Security and Privacy in Wireless & Mobile Networks, 105–16. WiSec ’14. New York, NY, USA: ACM. https://doi.org/10.1145/2627393.2627403.
Cornaglia, Bruno, and Marco Spini. 1996. “Letter: New Statistical Model for Burst Error Distribution.” European Transactions on Telecommunications 7 (3). Wiley Online Library: 267–72.
Gringoli, Francesco, and Lorenzo Nava. 2015. “OpenFWWF - Open FirmWare for WiFi networks.”
Lee, Jeongkeun, Wonho Kim, Sung-Ju Lee, Daehyung Jo, Jiho Ryu, Taekyoung Kwon, and Yanghee Choi. 2007. “An experimental study on the capture effect in 802.11a networks.” In Proceedings of the the Second Acm International Workshop on Wireless Network Testbeds, Experimental Evaluation and Characterization - Wintech ’07, 19. New York, New York, USA: ACM Press. https://doi.org/10.1145/1287767.1287772.
Neyman, Jerzy. 1939. “On a New Class of ’Contagious’ Distributions, Applicable in Entomology and Bacteriology.” The Annals of Mathematical Statistics 10 (1). JSTOR: 35–57.
Prasad, Rajan, Abhishek Kumar, Rahul Bhatia, and Bheemarjuna Reddy Tamma. 2014. “Ubersleep: An innovative mechanism to save energy in IEEE 802.11 based WLANs.” In 2014 Ieee International Conference on Electronics, Computing and Communication Technologies (Conecct), 1–6. IEEE. https://doi.org/10.1109/CONECCT.2014.6740349.
Santhapuri, Naveen, Romit Roy Choudhury, Justin Manweiler, Srihari Nelakuduti, Souvik Sen, and Kamesh Munagala. 2008. “Message in Message Mim: A Case for Reordering Transmissions in Wireless Networks.” In In Hotnets.
Schulman, Aaron, Dave Levin, and Neil Spring. 2009. “CRAWDAD Data Set Umd/Sigcomm2008 (V. 2009-03-02).” http://crawdad.org/umd/sigcomm2008/.
Wang, Wei, Wai Kay Leong, and Ben Leong. 2014. “Potential Pitfalls of the Message in Message Mechanism in Modern 802.11 Networks.” In Proceedings of the 9th Acm International Workshop on Wireless Network Testbeds, Experimental Evaluation and Characterization, 41–48. WiNTECH ’14. New York, NY, USA: ACM. https://doi.org/10.1145/2643230.2643231.
Zhang, Xinyu, and Kang G. Shin. 2012. “E-MiLi: Energy-Minimizing Idle Listening in Wireless Networks.” IEEE Transactions on Mobile Computing 11 (9): 1441–54. https://doi.org/10.1109/TMC.2012.112.
Atheros AR9280.↩
Available at https://github.com/Enchufa2/crap/tree/master/ath9k/downup.↩
For instance, this could be the ACK following a data frame or the CTS + data + ACK following an RTS.↩
Which is 32 768; see IEEE (2012a Table 8-3) for further details about the duration/ID field encoding↩
Note that this frame might be received because of the MIM effect explained previously.↩
E.g., by ITU-R (2005), Becam et al. (1985) and Irvin (1991).↩
E.g., \(\Delta t_\mathrm{w_{phy}}\) would be equivalent to our \(\Delta t_\mathrm{on}+\Delta t_\mathrm{ready}\).↩